

This post is part of Pattern Labs, our research initiative focused on translating real-world experimentation into defensible, production-ready workflows for mass tort litigation. This installment is a little different from previous entries. Rather than documenting a system we've built and deployed, it covers research I presented internally to the Pattern team, exploring the foundational AI infrastructure that sits one layer beneath our production systems. Specifically: how synthetic electronic health records are generated, why they matter for training reliable models, and what the privacy tradeoffs look like in practice. We study this work because it directly shapes how we build. That connection is the point.
One of the things I genuinely enjoy about working at Pattern is that we make time to learn. Not just learn about our own platform, but about the broader research landscape that our work sits inside. A couple weeks ago, I put together a session for the team on synthetic electronic health records: what they are, how they're generated, and why the AI community has invested so heavily in building them.
The conversation that followed reminded me why this kind of internal education matters. The team asked sharp questions. We connected the research to things we're already doing. And I left with a clearer sense of how this work applies to the problem we're actually trying to solve: reviewing complex medical evidence at scale, accurately, and in a way that firms can defend.
Here's what I covered, and why I think it's relevant to how we think about our platform.
Good AI needs good data
Training a machine learning model to understand medical records requires a lot of medical records. That's a straightforward statement with a complicated reality behind it.
Real patient data is tightly protected, as it should be. HIPAA and related privacy frameworks exist for good reason, and any responsible system has to respect those constraints. But that creates a genuine tension: the more data a model trains on, the better it generalizes. Rare conditions, unusual presentations, edge cases. These are exactly the kinds of things that show up in litigation, and they're also the hardest to represent in a training dataset that's assembled carefully and legally.
Synthetic electronic health records are one serious answer to this problem. The idea is to train a model on real data once, in a controlled environment, and then use that model to generate new patient records that are statistically realistic but not traceable to any real person. The output looks like real medical history. It follows real clinical patterns. But no actual patient is exposed.
From rules to neural networks
This field has evolved quickly. Earlier approaches used rules-based systems. Experts who understood clinical patterns would encode those patterns explicitly: if a patient has this condition, they're statistically likely to have this procedure, these lab values, this medication history. Systems like Synthea took this approach and did it reasonably well.
The limitation is obvious in hindsight: you can only capture what an expert explicitly codes. Rare correlations, the kind a model could learn from millions of records, get missed, or require enormous expert effort to surface.
Modern approaches lean on neural networks, specifically autoregressive language models, to discover those patterns rather than specify them. You train a large model on real EHR data, and the model learns the statistical structure of medical history on its own. Then you generate new records by sampling from that structure.
The model I focused on in my presentation is called HALO, short for Hierarchical Autoregressive Language Model. What makes it interesting is its approach to longitudinal records. Most models generate a single, independent medical record. HALO generates a sequence of medical visits for the same synthetic patient, building a coherent patient history over time. Each visit makes sense on its own, and the progression of visits makes sense together.
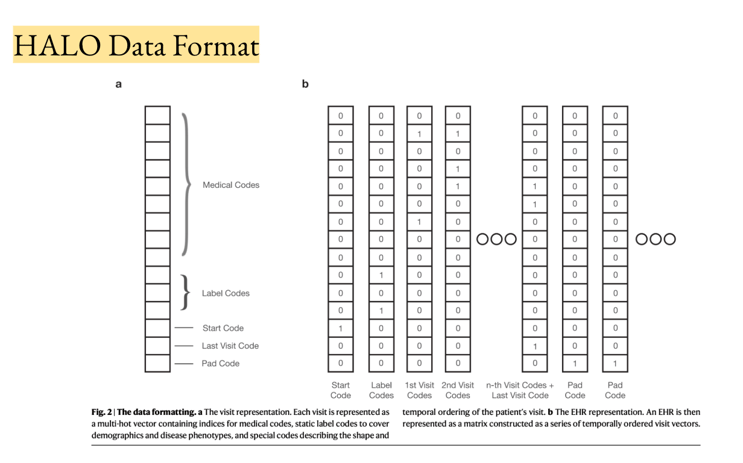
That matters for litigation work. We're not evaluating a single lab result. We're evaluating a case: a history, a timeline, a narrative built from dozens of records across multiple providers and years. A model that understands records as sequences is a better foundation for that kind of review than one that treats each page as an isolated document.
(Related: our team's work on improving document segmentation to preserve medical record context at scale.)
How can AI use medical records without compromising patient privacy?
Here's where the conversation in our team session got interesting, and where I want to spend a moment for the firms that work with us.
The whole motivation for synthetic data is privacy. But training a neural model on real patient records introduces its own risk: the model might memorize specific patients, not just learn general patterns. If someone probes the model carefully, they might be able to infer information about real individuals in the training set. This is called leakage, and it's a genuine concern.
The research community has developed rigorous methods for measuring and reducing this risk. One approach, differential privacy stochastic gradient descent, works by clipping how much any single record can influence the model's weights during training, and adding controlled noise to prevent the model from memorizing specifics. The result is a model that captures population-level patterns without being traceable to individuals.
There's an honest tradeoff here: more privacy protection often means slightly lower model performance, because the model is intentionally prevented from learning from outliers too aggressively. Getting that balance right is an active area of research, and it's not a solved problem. What we do know is that larger datasets help. The more records the model trains on, the less any single record can dominate.
Why this connects to what we build
Pattern's platform is built around the accuracy and defensibility of extracted data. Every condition date, every diagnosis, every exposure record we surface from a claimant's medical history needs to be right, and reviewers need to be able to verify it.
The models that power that work have to be trained on something. As we continue to improve how our system handles rare diagnoses, unusual record formats, and complex longitudinal cases, the quality and coverage of our training data directly affects what we can deliver from litigation development through settlement.
Synthetic EHR research is one of the foundational areas that makes better training data possible: data that can represent clinical edge cases without exposing real patients, and that can be generated at the scale required to build models that generalize rather than memorize.
We study this research carefully. We discuss it as a team. And we apply what we learn to how we build, because the firms that work with us are entrusting us with their clients' most sensitive information, and that's not something we take lightly.
The team at Pattern reads this research, debates the tradeoffs, and connects academic work to operational reality. The Q&A after this session, on dataset size, on the chicken-and-egg problem of needing data to generate data, on what it actually means to protect a real patient's record inside a model's weights, was some of the best technical conversation we've had internally.
That kind of rigor is what we owe the firms that work with us. Their clients' records are some of the most sensitive documents that exist. We think carefully about how AI handles that data, at every layer of the stack, including the layers most people never see.
Raj Patel is a machine learning engineer at Pattern Data.
Frequently asked questions
What are synthetic medical records?
Synthetic medical records are artificially generated patient records that preserve the statistical patterns of real electronic health records without representing any real individual. They are produced by training a generative model on real EHR data and then sampling new records from the patterns the model learned. The output looks like real medical history and follows real clinical sequences, but no actual patient is exposed.
Why do AI models for legal work need synthetic medical records?
Machine learning models that review medical evidence need volume and variety to handle the rare conditions, unusual presentations, and edge cases that appear across mass tort dockets. Real patient data is tightly restricted by HIPAA and similar frameworks, which makes assembling a large, representative training dataset difficult. Synthetic records let development teams train and test models on realistic data without compromising patient privacy.
Can AI memorize the patient records it was trained on?
Yes, and this is a real risk in synthetic data generation. A neural model trained on real records can sometimes memorize specific patient information rather than just learning general patterns. Researchers measure this and protect against it using techniques like differentially private stochastic gradient descent, which limits how much any single record can influence the model and adds controlled noise during training so individual patients cannot be reconstructed from the model's weights.
How does Pattern Data handle patient privacy in its AI?
Pattern's platform processes real claimant medical records inside firm-controlled environments. The synthetic data research described in this post informs how Pattern thinks about the broader AI training pipeline that produces our purpose-built models: ensuring those models generalize to rare cases, handle unusual record formats, and stay defensible at mass tort scale, while respecting the privacy expectations firms and their clients have a right to.